谷歌NLP新模型突破BERT限制
最近,谷歌又发布了另一款NLP机型,这个名字也叫"大鸟"!这只大鸟的特点是什么?在一次长时间的文字任务中,它的表现优于伯特?
谷歌最近推出了另一个引人注目的模式:Bigbird。
所有以前的刷牙伯特及其衍生版本的罗伯塔等,都是建立在变压器的基础上的。
这些模型的核心竞争力是完全关注机制,但这种机制会产生序列长度的二次依赖关系,如果输入令牌太长,它将支持内存,而在长文本摘要和其他任务中,伯特512令牌似乎有点牵强。
二级抚养限制Bert
在Bert中,令牌的长度一般设置为512,这对于普通的NLP任务来说已经足够了,但如果您想要挖掘整篇文章或一本书,即长文本任务,则令牌的长度有点短。如果将令牌的长度更改为1024,所需的计算量将是原始任务的4倍,这对内存非常有害。
如果你能降低这个n^2的复杂性,你就可以在不爆炸内存的情况下实现一种长距离的上下文注意力机制,这就是BigBird必须做的事情。
谷歌团队解决这个问题的方法是引入一种新的稀疏注意力机制:Bigbird。
谷歌大鸟:稀疏的注意力机制
与传统的完全注意机制相比,Bigbird变得更加稀疏。作为一种较长的序列,转换器Bigbird不仅可以关注更长的上下文信息,而且还可以将计算的二次依赖性降低到线性。
让我们来看看Bigbird是如何建造的。
图(A)显示r≤2的随机注意机制,图(B)显示w≤3的局部注意机制,图(C)显示g≤2的全局注意机制,图(D)是这三者的Bigbird模型。
图中的空白部分表示,只有在没有被注意到的情况下,颜色部分才会引起注意,这有点像有选择地丢弃辍学。
如果音符的部分减少了,性能也会降低,那么让我们来看一下实验结果。
实验:三种注意机制的结合是最好的。
只有随机的注意机制,局部的注意机制,或者两者的融合,三者的结合效果并不好。
Global+R+W更接近Bert基础、MLM任务,而不是Bert基础、班组和MNLI任务,但考虑到内存中节省了大量资源,它具有实用价值。
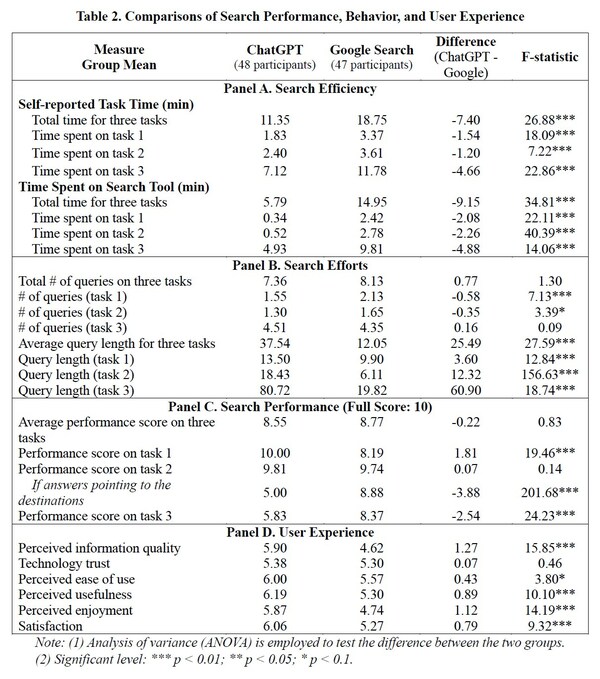
使用基本模型,对下列四项问答任务进行了测试:HotpotQA、NaturalQA、TriviaQA和WikiHop。结果表明,Bigbird的表现优于Roberta和Longver。
从长远来看,Bigbird在Arxiv、PubMed、Big专利权方面也表现出了良好的潜力,并取得了最好的效果。
使用这些数据集,因为它们都是长文档,所以通过输入512多个令牌,比较长文本的特征提取功能和模型的总体性能比较容易。
Reddit上的一些网友质疑Bigbird是另一种"龙鸟",没有必要的创新。
一些网友说,最近爆发的GPT-3也使用了稀疏的注意机制,但由于OpenAI块已经很长时间没有更新,所以不知道两者之间是否存在内在的相似性。
谷歌发表的一些研究以前已经提出过,但只有当谷歌发布时,它才能得到广泛的关注,而进入大工厂发表论文的可能性仍然很高。
期待大鸟给NLP任务带来新的惊喜!